This post will examine recent trends in artificial intelligence (AI) and its broader economic and geo-political implications.
The current interest in AI was triggered by the launch in November 2022 by Open AI of its ChatGPT, a generative AI solution trained with large language models (LLMs). Its versions and competitors have become fairly good at generating realistic writing, codes, videos, audio, and images. Successful applications have been in the generation of writing and codes.
As the name suggests, this type of AI uses LLM to recognise patterns and generate its outputs. Its ability to think, reason, and imagine has been limited, much less replicate human neural networks. Accordingly, it struggled with simple verbal and visual reasoning tasks that humans do with ease.
In recent months, there have been two important developments in AI’s journey. The first concerns the trends in the commercialisation pathways of AI, and the second involves the emergence of state-of-the-art AI models from China.
On the first, in September 2024, there was the release of new generative AI models that can “think” (reason, plan, and solve) on more complex problems. Though they too use the same underlying pattern-recognising models-based generative approach, they “think” harder about the task assigned to them by talking to themselves and spending more time on the model inferences. OpenAI released o1 in September and then o3 just before Christmas while Google released its Gemini Flash Thinking.
Such “thinking” AI models and solutions have been described as “digital versions” of Daniel Kahneman’s Type Two thinking (the LLM models that spit out its results quickly are the Type One models). These models indulge in structured, step-by-step thinking instead of blurting out their results.
This was accompanied by OpenAI and Google releasing generative AI solutions in the form of products (as against generative AI models like ChatGPT and Gemini). OpenAI released Sora, a video generation product, and Canvas, a writing and coding product, while Google unveiled Astra and Mariner. This productisation of AI solutions is a response to the growing chorus that for all its hype, AI is yet to realise significant commercial success for its users.
The two Google products belong to a new category of agentic AI tools that take actions on behalf of a user (as against chatbots that only talk), which raises the possibility of doing things in the virtual world like shopping on e-commerce sites or booking holidays and reservations.
Such models that “think” are a leap from those that quickly generate patterned answers like search engines, social networking, and chatbots. Once the fixed costs of model development and hardware investments are incurred, the marginal cost of the latter type of generative AI is very low. But models like o3 and agentic AI solutions use complex models whose processing requires more computing power, lots of memory, and low latency since they also interact with multiple tools like a web browser. They require more sophisticated hardware and consume more electricity. They can, therefore, be offered only as a subscription service.
In other words, while AI solutions have become more sophisticated, it’s also leading to a shift away from the world of low marginal cost services to the more traditional market of higher marginal cost products and services that come at a price. Accordingly, the “thinking” AI models and their productisation have the potential to transform the economics of the digital economy. Free or cheap services to large numbers at low marginal cost might become a thing of the past. The Economist has a good look ahead into the future of this market.
The power of such models relies on them bringing a version of the sector’s “scaling laws” closer to the end user. Until now, progress in AI had relied on bigger and better training runs, with more data and more computer power creating more intelligence. But once a model was trained, it was hard to use extra processing power well. As o3’s success on the ARC challenge (visual reasoning) shows, that is no longer the case. Scaling laws appear to have moved from training models to inference.
Such developments change the economics facing model-makers, such as OpenaiAI. The new models’ dependence on more processing power strengthens their suppliers, such as Nvidia... It also benefits the distributors of AI models, notably the cloud-service providers Amazon, Microsoft and Alphabet. And it may help justify the fortunes that these tech giants have invested in data centres because more inference will need more computing power. OpenAI will be squeezed from both sides…
High marginal costs mean the model-builders will have to generate meaningful value in order to charge premium prices. The hope, says Lan Guan of Accenture, a consultancy, is that models like o3 will support ai agents that individuals and companies will use to increase their productivity. Even a high price for use of a reasoning model may be worth it compared with the cost of hiring, say, a fully fledged maths phd. But that depends on how useful the models are. Different use cases may also lead to more fragmentation… providing AI services to corporate customers will require models that are specialised for the needs of each enterprise, rather than general-purpose ones such as Chatgpt. Instead of being dominated by one firm, some expect model-making to be more like a traditional oligopoly, with high barriers to entry but no stranglehold—or monopoly profits.
There’s a promise that the winner-takes-all dynamic of current technology markets could be upended. This is also amplified by the much reduced (or limited) network effects from such applications (compared to social media or search).
This development in the commercial prospects of generative AI products should be seen along with the developments in areas like robotics. In the first half of this year, Nvidia is set to launch Jetson Thor, a specialised computer to power sophisticated humanoid robots that can tackle complex tasks with great speed and efficiency.
Nvidia is positioning itself to be the leading platform for what the tech group believes is an imminent robotics revolution. The company sells a “full stack” solution, from the layers of software for training AI-powered robots to the chips that go into them…Robotics has so far remained an emerging niche that has yet to generate large returns… Data centre revenue, which includes its sought-after AI GPU chips, made up about 88 per cent of its overall sales of $35.1bn in the group’s third quarter… a shift in the robotics market is being driven by two technological breakthroughs: the explosion of generative AI models and the ability to train robots on these foundational models using simulated environments. The latter has been a particularly significant development as it helps solve what roboticists call the “Sim-to-Real gap”, ensuring robots trained in virtual environments can operate effectively in the real world…
Nvidia offers tools at three stages of robotics development: software for training foundational models, which comes from Nvidia’s “DGX” system; simulations of real-world environments in its “Omniverse” platform; and the hardware to go inside the robots as its “brain”… Amazon has already deployed Nvidia’s robotics simulation technology for three of its warehouses in the US, and Toyota and Boston Dynamics are among other customers using Nvidia’s training software.
Trends like the productisation of AI solutions, “reasoning” AI offering specialised services, humanoid robots etc., are potential revenue streams to sustain the AI revolution. Given the promising pipeline of such streams, massive cash surpluses with the leading tech companies, and the large physical investments required in computing power (and are being made), it’s not a stretch to imagine the giant AI bubble to keep inflating for a few more years before it gets pricked. Each trend has the potential to inflate bubbles that can sustain capital market valuations. The fact that the so-called magnificent seven firms stand to corner most of the benefits from these trends and they have also contributed almost all the gains in the S&P 500 over the last two years may point to further runway for the US equity markets, before the inevitable crash.
The second development in the AI space was news from China in December of its stunning progress in the new version of AI models. First Alibaba released its Qwen chatbot, QWQ, with similar “reasoning” capabilities, and originating from its own successive versions of generative AI LLM models. This was followed by news of progress made by others like ByteDance, Tencent, Moonshot, and o1.ai. The most remarkable news involved a small Chinese startup AI lab, DeepSeek, founded in 2023 by hedge fund manager Liang Wenfeng, which released its “reasoning” model, R1 (it had earlier released its regular generative AI model DeepSeek v3). This was developed with a small budget (model training was done in 2 months at a cost of $5.5 million), and apparently as a hobby by its eccentric founder who bought up several older versions of Nvidia GPU processors while running his successful quant trading hedge fund, High-Flyer.
In terms of performance, DeepSeek’s R1 appears to fall short of only o1. Among LLM models, DeepSeek v3 has 685 billion parameters, the individual precepts that combine to form the model’s neural network (the biggest among all models released for free download), compared to just 405 bn parameters for Llama 3.1, Meta’s latest LLM. The Economist has a good set of graphics that compare the performance of DeepSeek.
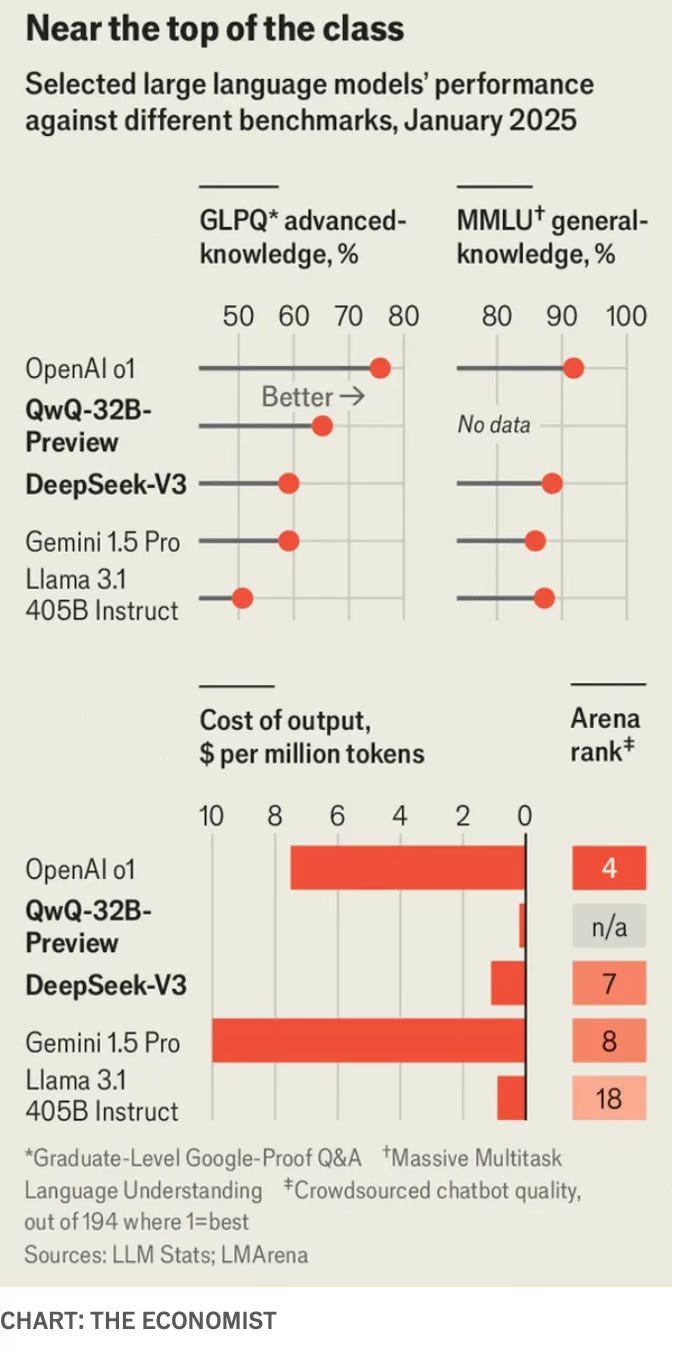
The exceptional feature of DeepSeek’s success was that it could develop its “reasoning” models without access to the latest Nvidia H100 GPU chips that OpenAI and others have in plentiful numbers.
DeepSeek claimed it used just 2,048 Nvidia H800s and $5.6mn to train a model with 671bn parameters, a fraction of what OpenAI and Google spent to train comparably sized models.
The v3 LLM’s billions of parameters took fewer than 3 m chip hours, a tenth of the computing power and expense that went into Llama 3.1, and its training requirement of just above 2000 chips compared with Llama 3.1’s 16,000 chips and that too of a higher version. Meta is now planning to build a server farm with over 350,000 chips and Elon Musk’s xAI is planning one with over a million chips.
To reduce reliance on high-end chips from overseas, Chinese AI companies have experimented with novel approaches in algorithms, architecture and training strategies. Many have embraced a “mixture-of-experts” approach, focusing on smaller AI models trained on specific data. These can deliver powerful results while reducing computing resources… DeepSeek completed training in just two months at a cost of $5.5mn… DeepSeek has also drastically reduced inference costs, earning it the nickname the “Pinduoduo of AI”, a reference to the cost-slashing business model of the popular Chinese discount ecommerce giant. This breakthrough has profound implications. It challenges the widely held assumption that cutting-edge AI requires vast amounts of computational power and many billions of dollars. DeepSeek demonstrates how software ingenuity can offset hardware constraints… strict export controls have forced Chinese tech companies to become more self-reliant, spurring breakthroughs that might not have occurred otherwise.
Clearly, Chinese companies are figuring out innovative ways to maximise the computing power of a limited number of older generation chips, the Chinese version of Indian jugaad innovation. Having said this, there are also disputing voices like this who claim that the actual number of chips is higher.
As an aside, DeepSeek’s apparent parsimony and efficiency point to multiple paradoxes. It exposes the profligacy and inefficiency of Big Tech with its vast funding pool and sub-optimality of use cases. It also stands in stark contrast with China’s own industrial policy on semiconductor chip making, which appears riddled with waste and inefficiency. It highlights the benefits of scarcity and constraints in expanding the frontiers of innovation. When finance does not have any disciplining force, as is the case with Big Tech spending on AI and the private capital funding globally over the last fifteen years or more, the market may be no better than governments in allocating finance by safeguarding against excesses and waste.
DeepSeek is not only remarkable in being at the cutting edge but also in being disruptive in other ways. It also revealed the technical recipe or the training model and methods (unlike OpenAI and Google, which have kept their methods confidential) in a detailed paper that outlines how to build a LLM that can learn and improve itself without human supervision. By releasing its technical recipe, it has opened up the possibilities for open-source AI and future business models for such endeavours in the US and elsewhere. In fact, here, DeepSeek has been following the route that appears to have been adopted by Chinese companies in general of making their systems available on an open-source license.
If you want to download a Qwen AI and build your own programming on top of it, you can—no specific permission is necessary. This permissiveness is matched by a remarkable openness: the two companies publish papers whenever they release new models that provide a wealth of detail on the techniques used to improve their performance. When Alibaba released QWQ, standing for “Questions with Qwen”, it became the first firm in the world to publish such a model under an open licence, letting anyone download the full 20-gigabyte file and run it on their own systems or pull it apart to see how it works. That is a markedly different approach from OpenAI, which keeps o1’s internal workings hidden… Ask QWK to solve a tricky maths problem and it will merrily detail every step in its journey, sometimes talking to itself for thousands of words as it attempts various approaches to the task. “So I need to find the least odd prime factor of 20198 + 1. Hmm, that seems pretty big, but I think I can break it down step by step,” the model begins, generating 2,000 words of analysis before concluding, correctly, that the answer is 97.
This openness also points to a less discussed attractiveness to talented AI programmers and professionals.
Chinese labs are engaged in a battle for the same talent as the rest of the industry. Eiso Kant, the co-founder of Poolside, a firm based in Portugal that makes an AI tool for coders says, “If you’re a researcher considering moving abroad, what’s the one thing the Western labs can’t give you? We can’t open up our stuff any more. We’re keeping everything under lock and key, because of the nature of the race we’re in.” Even if engineers at Chinese firms are not the first to discover a technique, they are often the first to publish it, says Mr Kant. “If you want to see any of the secret techniques come out, follow the Chinese open-source researchers. They publish everything and they’re doing an amazing job at it.” The paper that accompanied the release of v3 listed 139 authors by name, Mr Lane notes. Such acclaim may be more appealing than toiling in obscurity at an American lab.
Chinese companies appear to be showing the world a different model for AI solutions compared to the restrictive approach adopted by US Big Tech firms.
It has also avoided raising money from outsiders, with Liang paying top salaries to its AI developers using his income from his hedge fund.
“DeepSeek is run like the early days of DeepMind,” said one AI investor in Beijing. “It is purely focused on research and engineering.”… “DeepSeek’s offices feel like a university campus for serious researchers,” said the business partner. “The team believes in Liang’s vision: to show the world that the Chinese can be creative and build something from zero.”.., Liang has styled DeepSeek as a uniquely “local” company, staffed with PhDs from top Chinese schools, Peking, Tsinghua and Beihang universities rather than experts from US institutions. In an interview with the domestic press last year, he said his core team “did not have people who returned from overseas. They are all local . . . We have to develop the top talent ourselves”. DeepSeek’s identity as a purely Chinese LLM company has won it plaudits at home.
Its singular focus on research (at least to date) and disinterest in monetising its models is a throwback to Silicon Valley in its early years. In fact, its focus on AI for the public good is reminiscent of OpenAI’s own founding ethos as a non-profit, one which it quickly sprinted away from once the commercial prospects became evident, in keeping with American capitalism’s reflexive pursuit of profits.
Its small size and bootstrapped nature raise questions about entry barriers and the impregnability of AI leaders like Open AI, Google, Meta, Anthropic etc. In general, its approach threatens tech firms that have created a small oligopolistic club interested as much in keeping out emerging competitors (kill-zone) as in innovation. It’s also remarkable that such a market-upending innovation and business model has not emerged in the supposedly innovation-friendly US but in China.
However, it remains to be seen as to how long can this Chinese catch-up continue without access to the rapidly growing sophistication and power of computing (Nvidia’s new generation Blackwell chips, use of more and more advanced chips to increase computing power etc.). There surely has to be a limit to how much ingenuity and innovation alone can do to make up for the sheer physical brutality of hard computing power. And especially when the US is doubling down on its own AI efforts, as evidenced by the new $500 bn investment announcement on the Stargate project involving Oracle, OpenAI, and Softbank. It’s hard to not feel that the gap will widen.
Finally, the rise of DeepSeek and Chinese models raises uncomfortable questions for India’s software firms and startups. Despite having a head start of over half a century of competing in the global software industry, India’s iconic software firms have struggled to move beyond their low-value-capture business models. They have also failed to capitalise on successive technology waves like cloud computing, IoT, data analytics, and robotics, and now the same appears to be happening with AI, too. The startups, too, have been one step removed from the frontier, mostly focusing on copying and improving successful innovations and business models from the West.
As the Chinese successes show, a combination of enterprise and reasonable funding can help leapfrog physical constraints to vault to the cutting edge of innovation in areas like AI and other cutting-edge software. India has AI talent, a well-developed startup ecosystem, and pockets of reasonable funding (tech and other billionaires) to be able to engage at the cutting edge.
But it appears to lack the enterprise and ambition among its entrepreneurs and wealthy individuals from the technology and finance sectors to spawn a DeepSeek and Liang Wengfeng. The former appears happy enough copying successes from the West and adapting them for local markets, and the latter prefers to invest all their wealth in the public markets. Reluctance to defer gratification and risk aversion appear to be characteristic features of startups and investors.
It’s one more example of how the private sector and its enterprise have lagged in supporting India’s high economic growth aspirations.
No comments:
Post a Comment