I have not blogged about AI in development. One reason is that, notwithstanding several claims, I have not come across promising examples that have been successfully applied at a reasonable scale within public systems in the Indian context.
I have blogged here, urging caution on the expectations of the impact of AI on development in countries like India. The central argument is that the binding constraint on AI impact in the public sector is rarely technical capability. It is the gap between what AI can do and what institutions are prepared to validate, adopt, and integrate, a gap shaped by the validation cost, regulatory frameworks, incumbent system stickiness, and the political economy of transition.
As an analytical framework for the application of AI in development, I can think of three lenses: the layer where the AI intervention is proposed, the nature of the problem to be addressed, and the constraints on deployment and adoption.
In the first lens, AI can provide structured information to feed into decision-making; or directly enable decision-making by synthesising information into ranked options or risk scores, thereby augmenting human judgment; or deliver specified outputs in the form of drafts, transaction alerts, assessments, etc.
The second lens can distinguish between complicated/complex and wicked problems. The former has many variables but is tractable with better data and modelling (crop yield prediction, supply chain optimisation, credit risk scoring, traffic signal timing, etc.), whereas the latter involves contested goals, adaptive actors, and systemic feedback (improve learning outcomes or skills, institutional reform, manage urban growth, etc.). While there are limits to AI, especially in the latter, complicated sub-problems within the former are amenable to AI.
The third lens covers the gap between technical feasibility and deployed impact. This gap is shaped by validation cost (regulatory standards must be met), the incumbent system stickiness (when the AI solution demonstrates value that helps overcome the systemic inertia), trust and legitimacy (system or society must accept the efficacy and reliability), and political economy (overcome the entrenched vested interests).
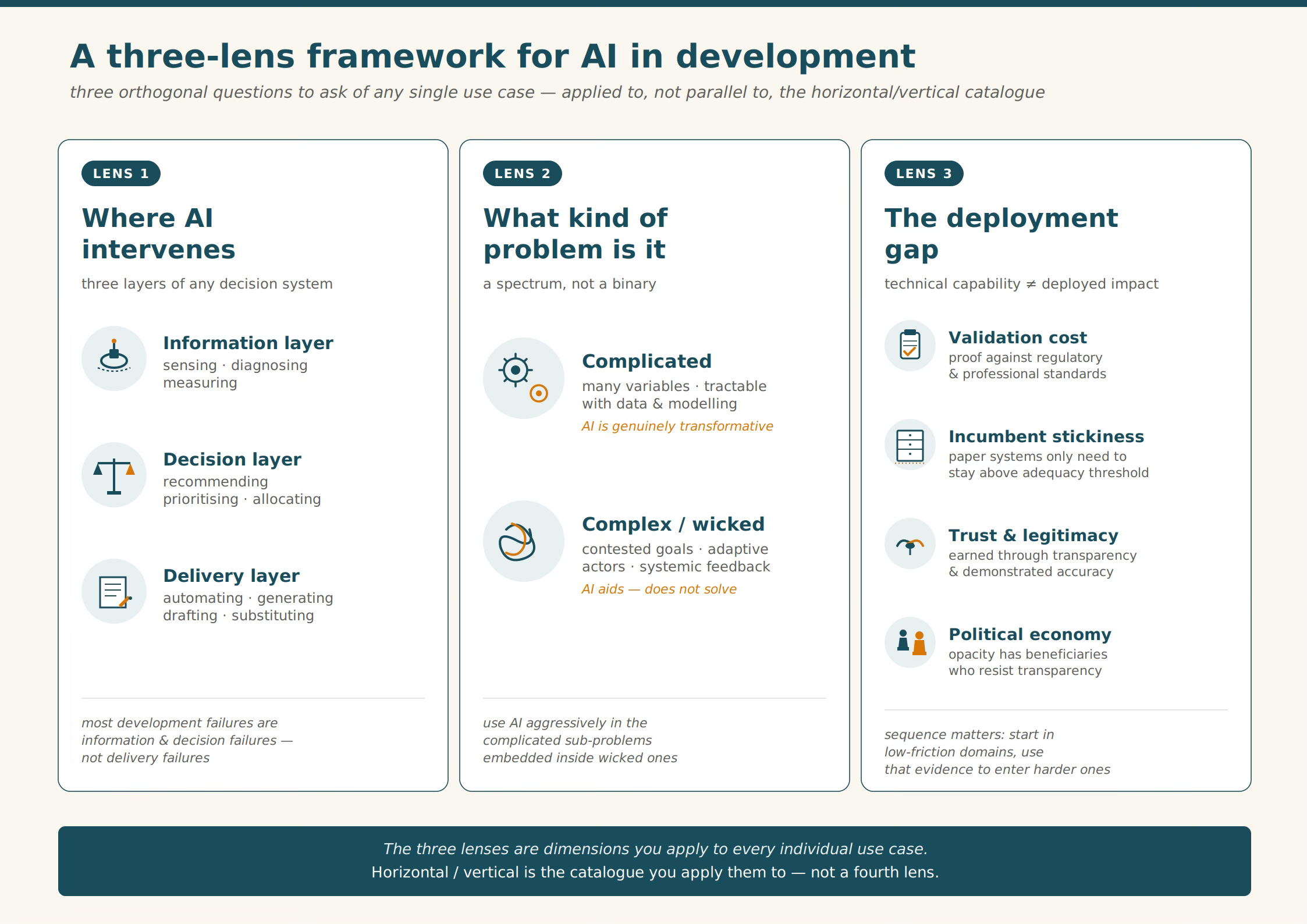
The three lenses are analytical dimensions, or orthogonal axes on which any individual intervention can be located. Then we have the horizontal or vertical use cases, which are a typological cut across the universe of interventions. It sorts use cases by their organisational footprint (does this sit in every department or only one) rather than analysing the nature of any single use case.
The graphic below applies the three lenses to each item in an illustrative catalogue of horizontal/vertical use cases.
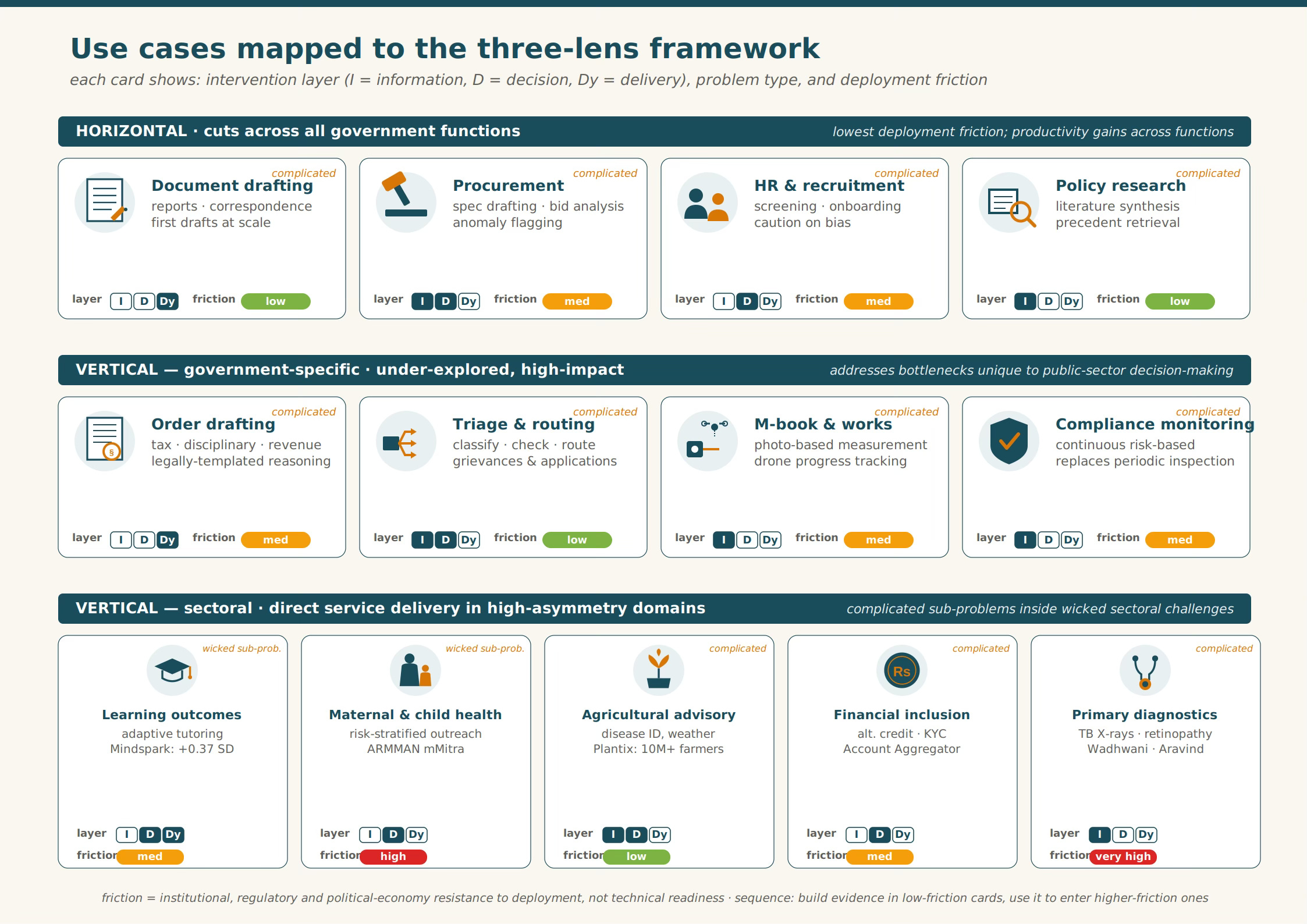
As a prudent strategy, it may be useful to move first in low-friction domains - where there are no regulatory incumbents, where information asymmetry is high, and where the beneficiary is a motivated adopter - and use the evidence and trust built there to lower the political cost of adoption in high-friction domains. In this reading, as is the trend in the private sector, it will be some time, if ever, before vertical sectoral use cases of AI become efficacious and reliable enough to be adopted at scale.
Based on the above, what are the most valuable and widest spanning productivity and efficiency increasing uses of LLMs by governments in developing countries (with low state capabilities)?
I can think of two in particular - application in the generation of quasi-judicial and adjudication orders of all kinds, and in the recording of M-Book in engineering works. The breadth of their use, the stakes involved, the low current baseline, and the manageability of their deployment gaps make them areas with potentially transformative impacts.
The first one ranges from charge sheets to orders in service matters and disciplinary cases, to regulatory and licensing decisions, assessment and adjudication by tax, land, and other authorities exercising statutory powers, including court and tribunals.
Each of these has a standard structure - factual matrix, applicable legal provisions, consideration of arguments, findings, and operative order - that AI can populate with high-quality given structured inputs. The official provides the facts and the decision, and AI generates the legally coherent reasoning and formal language.
The value of this comes from the low baseline of generally poor quality of orders issued that suffer both from basic procedural/hygiene deficiencies and more substantive application of judgment. These deficiencies and lapses, especially of the former kind, immediately invite disputes. In fact, such poorly crafted orders become the starting point for a long series of administrative processes that manifest in disputes and harassment, appeals and litigations, that clog administrative bandwidth, lock up scarce capital, impair balance sheets, and generally waste effort and resources.
These kinds of orders also contribute a very large share of the litigation against the government that clogs the judiciary. The major reason why governments lose such cases is the quality of orders in terms of poor drafting and adherence to basic administrative compliance and procedures. Poorly drafted orders are often set aside, not because the underlying decision was wrong, but because the reasoning was inadequately articulated. AI can have a significant impact in this area in both improving the quality of orders and even forcing systems to comply with procedural requirements.
The volume of such orders is enormous. A mid-level income tax officer may need to issue hundreds of assessment orders annually; a district collector may handle thousands of revenue proceedings. The drafting burden is a critical bottleneck in disposal rates. Further, AI-generated drafts can be trained to flag inconsistencies, missing procedural steps (e.g., failure to give opportunity to be heard), and citation of superseded legal provisions, thereby acting as a compliance check before the order is issued.
An AI application that generates the first draft of the order, for the adjudicating officer to revise and issue, can have a transformative cascading impact down the chain. The first draft can be hard-coded to serve as a forcing function to ensure compliance with a checklist of processes; the order itself could be validated, and its logic could also help with tightening the substantive exercise of judgment itself.
On the face of it, this is a low-hanging fruit. All it requires is a library of orders of all kinds bundled together, and a template for different kinds of orders. An enterprise or team subscription to Claude or OpenAI, that has a Zero Data Retention (ZDR) configuration for their API (thereby ensuring customer data is not retained and used for training the algorithm), and which allows access to Claude through Amazon Bedrock or Azure OpenAI within a private Virtual Private Cloud, can address any privacy and security concerns on sharing internal data.
This would be a quick deployment and superior to any indigenous or sovereign LLM model development (which should continue and could perhaps be deployed in parallel to learn and get refined).
The latter work can be taken up in a mission mode by the National Informatics Centre or a public think tank (say, the National Centre for Good Governance, NCGG) by deploying a team of competent experts. It can consolidate the library of orders and develop standardised LLMs for a few high-volume and value use cases - disciplinary cases, GST and income tax adjudication orders, and orders on a few categories of land claims settlements. They could work with a few state governments, the CBIC (state indirect tax departments), and the CBDT.
The other high-value and promising application can be in the recording of the Measurement Book (or M-Book) for engineering works - roads, buildings, canals, drains, electricity lines, etc. It records the quantity of work done, certified by a junior engineer, against which payment is authorised. It is also one of the most fraud-prone documents in public works administration, susceptible to over-measurement, fictitious entries, and post-facto alteration. Besides, it is also a procedurally burdensome activity. Its importance arises from the fact that it is the basis on which contract payments are made.
For certain categories of works, AI-assisted quantity and quality measurement from photographs and drone-based progress tracking and volume estimation can be very reliable. Smartphones equipped with computer vision applications can estimate dimensions and quantities from site photographs (lengths of pipes laid, areas of surface plastered, volumes of earthwork excavated). Computer vision models can be trained to assess the quality of construction work from photographs by detecting visible defects in concrete, checking alignment of masonry, and identifying sub-standard finishing. For large civil works (earthwork, embankments, reservoirs, large buildings), drone imagery processed through photogrammetry software can generate accurate volumetric estimates and three-dimensional progress models.
At the very least, AI-assisted photographs and drone outputs can be used to validate M-Book entries, surface quality concerns and other discrepancies. Once M-Book entries are digitised, AI can generate contractor bills from certified measurements, cross-check against contract rates, identify arithmetic errors, flag unusual patterns (e.g., a sharp increase in claimed quantities near bill submission deadlines), and route completed bills for authorisation. Apart from improving the quality and increasing accuracy of payments, the time savings and reductions in delays in payments will be significant.
The examples of order-drafting and M-book opportunities are likely to be particularly appealing for officials because they also significantly reduce their workload and drudgery. They are deployable at medium friction, directly legible to senior officials, and capable of generating rapid, measurable impact that builds institutional confidence in AI tools.
Another area of promise is the categorisation or triaging of cases in several public domains.
The Ken has an article on the application of AI by courts in India. A promising application of AI is in the categorisation and triaging of cases.
Half of India’s backlog—25 million cases—could disappear quickly if AI were used not to decide cases, but to triage them. The opportunity lies in the huge volume of matters that are effectively already dead on arrival: cases filed beyond limitation, petitions missing mandatory disclosures, matters rendered moot by changes in law, or disputes where precedent has already settled the question, leaving only a narrow technical point to close. Courts identify these only in occasional manual clean-ups—slow, inconsistent, and impossible to scale.
An AI system, by contrast, could scan filings in bulk, flag statutory defects, detect outdated or defective pleadings, classify time-barred matters, and surface cases appropriate for summary disposal. These could then be bundled and placed before judges for quick orders, clearing the undergrowth so courts can focus on disputes that actually require judicial time.
Like with court cases, triaging of outpatient (OP) cases in primary health centres (PHC), community health centres (CHC), district hospitals, and medical colleges is an area where AI can play a potentially significant role. The daily OP load in these hospitals (at least the better ones among them) is multiples of what a doctor can manage, leaving them overburdened and stressed. The result is inefficient use of the doctor’s time, inadequate diagnosis time, incorrect diagnosis, wrong OP referrals, and so on.
In all these hospitals, OP cases come to doctors with limited or no triaging. An AI-based triaging application where the symptoms are entered at the OP-registration, nurse and doctor-level, can significantly improve work conditions, increase hospital productivity, and enhance the quality of treatment.
Similarly, citizen grievances or consumer complaints received in any office, especially public-facing ones, can be triaged for routing them to the right desks/officials, escalating to senior officials, analysing repeat complaints, and so on.
Triaging is already one of the early emerging successes of AI, with examples like Bank of America’s digital assistant “Erica”, which handles billions of client interactions and has reduced call centre volumes by 40 per cent.
In general, the judiciary’s case load management is an area where, in theory, AI applications can have a transformative impact, especially in categorising cases, transcription of witness statements, and the preparation of orders. The Ken article has a good description of an AI application in a courtroom in Kerala.
A witness spoke; an AI-powered tool listened. A clean, searchable transcript appeared in real time—punctuated, structured, permanent. Stenographers were not clambering to catch up, litigants were not begging for readable copies. This split-screen view—one courtroom running on memory, the other on machine comprehension—is not a metaphor. It is India’s judiciary in 2025: a system where 19th-century workflows and modern AI systems operate side by side, neither quite replacing the other. Earlier in 2025, the Kerala High Court issued an office memorandum, making AI-assisted live transcription mandatory across all district courts…
“Today, the AI-transcribed witness testimony is uploaded as soon as the proceedings are completed. Earlier, the witness testimony would be handwritten by the judge, and a party’s lawyer would apply for a readable copy and seek adjournment on that basis,” said Joseph Rajesh, the IT Registrar of the Kerala High Court. “All this time delay is now cut down to nil.”… A court order that once took four or five hours to type can now be generated in under an hour. A witness deposition that once required handwritten dictation, shorthand transcription, and final review can be captured in a single digital stream.
The article also has this graphical exploration of the various possible use cases for AI within the judiciary.
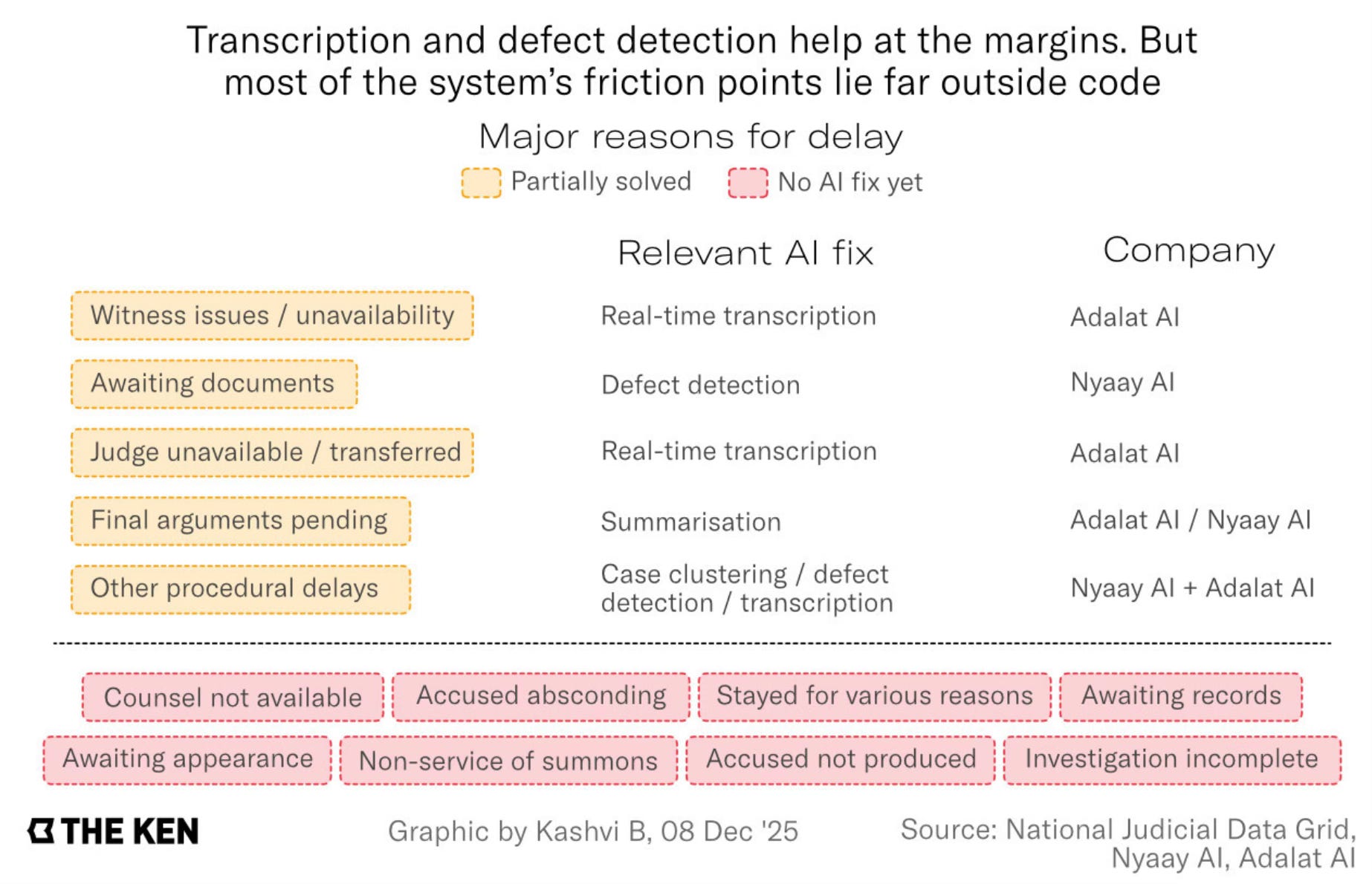
There can also be daunting practical challenges to its adoption
Consider defect detection—the clerical step where filings are checked for completeness. In Delhi’s Tis Hazari courts, the rules are so complex that Nyaay’s engineers joked: If we can crack defect detection here, we can crack it anywhere. The joke holds true. AI had to be customised court by court. And transcription? In many urban courts, there are stenographers, but in district courts, they are scarce. AI fills a vacuum, but only if the court has electricity, microphones, and a judge willing to trust the output.
So how can these AI applications be deployed?
For all these use cases, the development of robust AI applications that can be deployed across institutional levels nationwide is an industrial engineering endeavour. It requires diligent, long-drawn, and high-quality problem-solving, including pilots (or beta testing), iterative adaptation and refinement. It cannot be achieved by an experiment undertaken by a district or state-level entity (or even as ad-hoc officer-driven initiatives within central government departments), as is often the case today.
The Ken article cited above points out the problems of not having one entity in charge of the creation of these national public goods.
The downside is that every state is effectively running its own lab experiment: non-standard, improvised, and dependent on the priorities (or disinterest) of whoever happens to be leading the High Court. Some innovate aggressively. Some slow-walk. Some judges independently approach AI companies, but without formal approval, nothing can enter the courtroom workflow… High Courts and district courts continue testing tools piecemeal. Language models multiply while vendors proliferate and workflows diverge… India could end up with 25 distinct judicial AI ecosystems, none interoperable, standardised, or scalable nationally…
India’s AI push is happening largely outside the Supreme Court’s flagship e-Courts project—the initiative meant to modernise the judiciary. Phase III of the programme still focuses on the basics: creating digitally readable records, enabling e-filing, and automating service of summons. A February Press Information Bureau note pegs the Phase III budget at Rs 7,200 crore, but only a little over Rs 50 crore is reserved for “integration of AI and blockchain technologies across High Courts”. In effect, the national blueprint is still laying the plumbing while the states are already experimenting with smart faucets…
If India manages to fuse Kerala’s mandate with Karnataka’s case clustering, Delhi’s defect detection, the Supreme Court’s governance frameworks, and the entrepreneurial urgency of tools like Adalat and Nyaay, the judiciary could undergo a systemic leap.
It would require a dedicated team at the national level (government department, Supreme Court, CBIC/CBDT, etc.) engaging single-mindedly on the endeavour - formulating the problem, collecting and cleaning data, developing models for different levels of government, undertaking pilots with close oversight, iterating with tight feedback loops, documenting processes, and scaling solutions gradually.
The models required for lower courts, High Courts, and the Supreme Court would vary and must therefore be customised, just as those required for hospitals of different kinds, tax and land adjudicating and appellate officials at different levels, and disciplinary authorities for different kinds of functional entities. In each case, there would be a need to do rigorous pilots to be able to refine and finalise robust enough solutions that can be deployed at scale.
No comments:
Post a Comment